
2k+ GitHub Stars, Partition Writes, and a Sneak Peek at Daft Launcher!
Kicking off the 1st edition of the Daft Newsletter

Introducing the Daft Newsletter! Each month, we will recap the projects we’ve been working on, share some exciting developments that are in progress, and highlight what’s on the horizon for Daft.
September Rewind ⏪
At the end of August, we released v0.3.0 of Daft. The journey from v0.2 to v0.3 saw 636 commits in 34 releases from 41 contributors. Numerous new features were added, and along the way, we picked up over a thousand GitHub stars. In September, we hit two huge milestones: 2,000 GitHub stars and 2,000 GitHub commits. Actually, as we write this newsletter, we’ve surpassed 2,100 stars!

The growth has been wild — thank you to our growing community, we have the utmost appreciation for you all! If you haven’t starred our repo, what are you waiting for? → Daft Repo
Blogs 📝
If you’d like to learn how to leverage Daft to efficiently read and manage data governed by Unity Catalog in Databricks, check out the blog post written by Databricks solution architects Pascal Vogel and Kiryl Halozhyn. → How to access data in Databricks from Amazon SageMaker notebooks

Presentations 🧑🏻💻
The MLOps Community hosted a Data Engineering for AI/ML conference where Jay addressed a major pain point in data engineering—handling diverse data types in machine learning workloads. Watch the recording to learn how Daft simplifies multimodal data curation by utilizing S3 and Parquet, handles workloads of hundreds of TB effortlessly, and ensures a streamlined workflow by integrating ETL, analytics, and data loading functions.
The team also presented at the SF Systems Meetup hosted by Chroma. Desmond Cheong kicked off the talk by introducing Apache Spark, discussing its origins, highlighting its strengths, and addressing its current limitations in terms of performance and stability. Colin Ho then followed this by sharing how we are designing Daft’s local execution model to outperform Spark and going over the decisions between push- vs. pull-based execution, partition vs. morsel parallelism, and bulk synchronous vs. streaming data flow.



Videos 📺
September’s Contributor Sync featured updates about our complete support for writing to partitioned Iceberg and Delta tables, running SQL in Daft and our updated documentation with SQL code examples, and the latest progress on Project Swordfish, which has shown DuckDB-like local performance.
September’s Data Topic Deep Dive focused on Raunak Bhagat’s current work on Daft Launcher. Daft Launcher is a small and convenient CLI tool for getting started with running Daft on a distributed cloud cluster. No more need to worry about the complexities of managing Ray—you can simply run a few convenient CLI commands to spin up, spin down, interact with, and observe the status of your cluster. This frees you up to focus on learning Daft!
Make sure to add the Daft Monthly Contributor Sync to your calendar and join us for next month’s! → https://bit.ly/DaftContributorSync
Work in Progress 👀
Daft-SQL 🗄️
We had an exciting launch last week—pioneered by Cory Grinstead, Daft-SQL is our new SQL API that enables users to interact with their data in a new but familiar way. Whether you’re analyzing large datasets or performing simple queries, you can now interact with your data using traditional SQL queries within the Daft ecosystem. Daft-SQL offers a streamlined, SQL-based interface that simplifies your workflow!
Here’s a sneak peak:
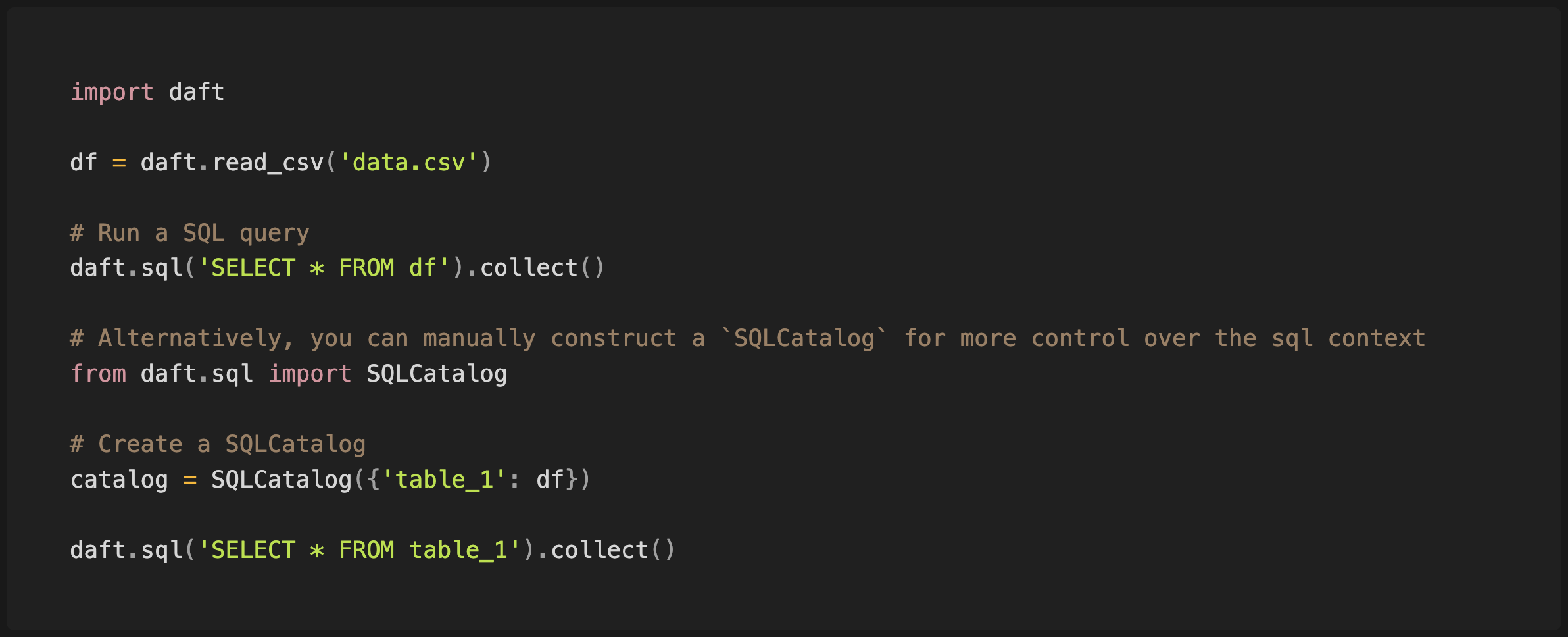
If you’re eager to learn more, a blog post is coming soon where you can dive into the tips & tricks of using Daft-SQL.
Partition Writes 📄
Kevin has been working on supporting partitioned writing for Iceberg and Delta Lake. Once these features are implemented, Daft will have the best write support for Iceberg outside of Spark! Expect these updates to drop in the next release.
The final feature to support after this is upserts. If you have any thoughts about upsert support in Daft, drop by our Slack for a chat!
Looking Forward to October 🎃
Project Swordfish 🗡️🐟
Colin has been spearheading Project Swordfish, Daft’s new streaming execution model designed to deliver faster and more memory-efficient execution on a single node/local machine. The fully streaming, push-based engine has shown up to 50% improvements in both speed and memory usage compared to our previous executor, as well as Apache Spark.
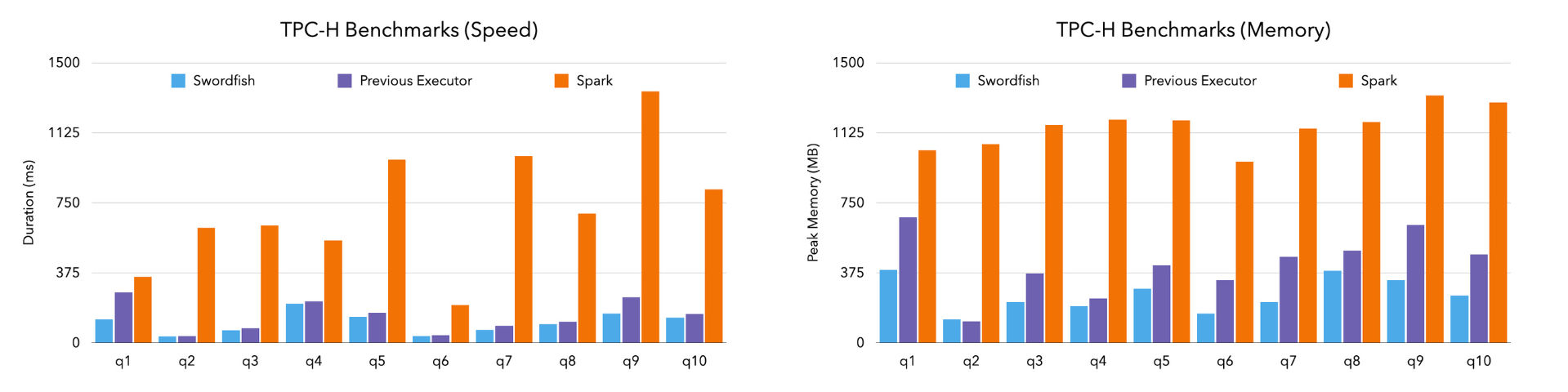
Swordfish is currently in its final phases of completion. We’re targeting a mid-October beta release where you will be able to use this new executor by setting daft.context.set_runner_native().
Events 🎟️
We have two events upcoming in October as part of a16z’s SF Tech Week, and a community meetup scheduled for early November.
Multimodal Data with Modern Tools
Tuesday, October 8 | 5pm – 8pm
Modern AI/ML workloads require data infrastructure that is capable of handling the complexity of multimodal data. AI/ML is no longer about simple tabular features or clickstream data—modern AI/ML demands data infrastructure that can handle messy unstructured text, documents, images, and even video.
Meet the team building Daft and experts from Twelve Labs, LanceDB, and Databricks. Dive into innovative solutions tackling the growing demands for AI/ML data infrastructure that can effectively handle diverse types of unstructured data such as text, documents, images, and even video. Registration closes Friday, October 4.

From Data to Deployment: Lessons from AI Founders
Thursday, October 10 | 5pm – 8pm
Calling founders and engineers! Join us for an exclusive panel discussion featuring AI leaders & startup founders from Happyrobot, Overview, Mozart Data, and Eventual as they share their hands-on experiences with building robust data pipelines, managing complex datasets, and overcoming challenges with scaling AI solutions.
Co-hosted by Eventual & Array Ventures, come for the panel and stay for the happy hour afterwards! Registration closes Tuesday, October 8.

Apache Iceberg Bay Area Community Meetup
Monday, November 4 | 5pm – 8pm
We’re hosting the next Apache Iceberg Bay Area Community Meetup in November! If you’re interested in giving a presentation and sharing your Iceberg best practices and expertise with the community, submit a talk by Wednesday, October 9.
Join Our Team! 🌟
We’re excited to announce that we’re expanding our team! At Eventual, we’re dedicated to fostering innovation, collaboration, and growth. We’re looking for passionate individuals with a strong sense of intellectual curiosity who are eager to make an impact and contribute to our mission.
If you thrive in a dynamic environment and want to be part of a supportive community, we’d love to hear from you. To learn more about what we’re building at Daft and how you can help, head to our Careers Page and apply today!
If you haven’t already, join our Distributed Data Community Slack and star our Daft GitHub repo! Engage in technical conversations with our engineers about Daft developments and stay in the know about the latest Daft news and updates.
Join us for the next Daft Monthly Contributor Sync on Thursday, October 31. Add it to your calendar! → https://bit.ly/DaftContributorSync