Let’s talk about smallpond and 3FS, two open-source projects released by the DeepSeek team last week.
The DeepSeek team started off as a high-frequency trading (HFT) company but is now better known as a AI lab, infamously released DeepSeek R1 which took the AI world (and the US tech stock market) by storm. A few weeks ago, DeepSeek open-sourced some of the tooling their team uses internally, including their distributed filesystem 3FS and data processing framework smallpond.
Thanks for reading Daft Engineering Blog! Subscribe for free to receive new posts and support our team’s work!
But beyond the hype, let’s dig into a few key questions:
How impressive are the numbers presented here, really?
Is “data processing for AI” just a buzzword, or does it actually matter?
Realistically, can/should I be using smallpond + 3FS?
Let’s do a 5 minute speedrun introduction to the 3FS/smallpond systems.
3FS and smallpond: the rundown
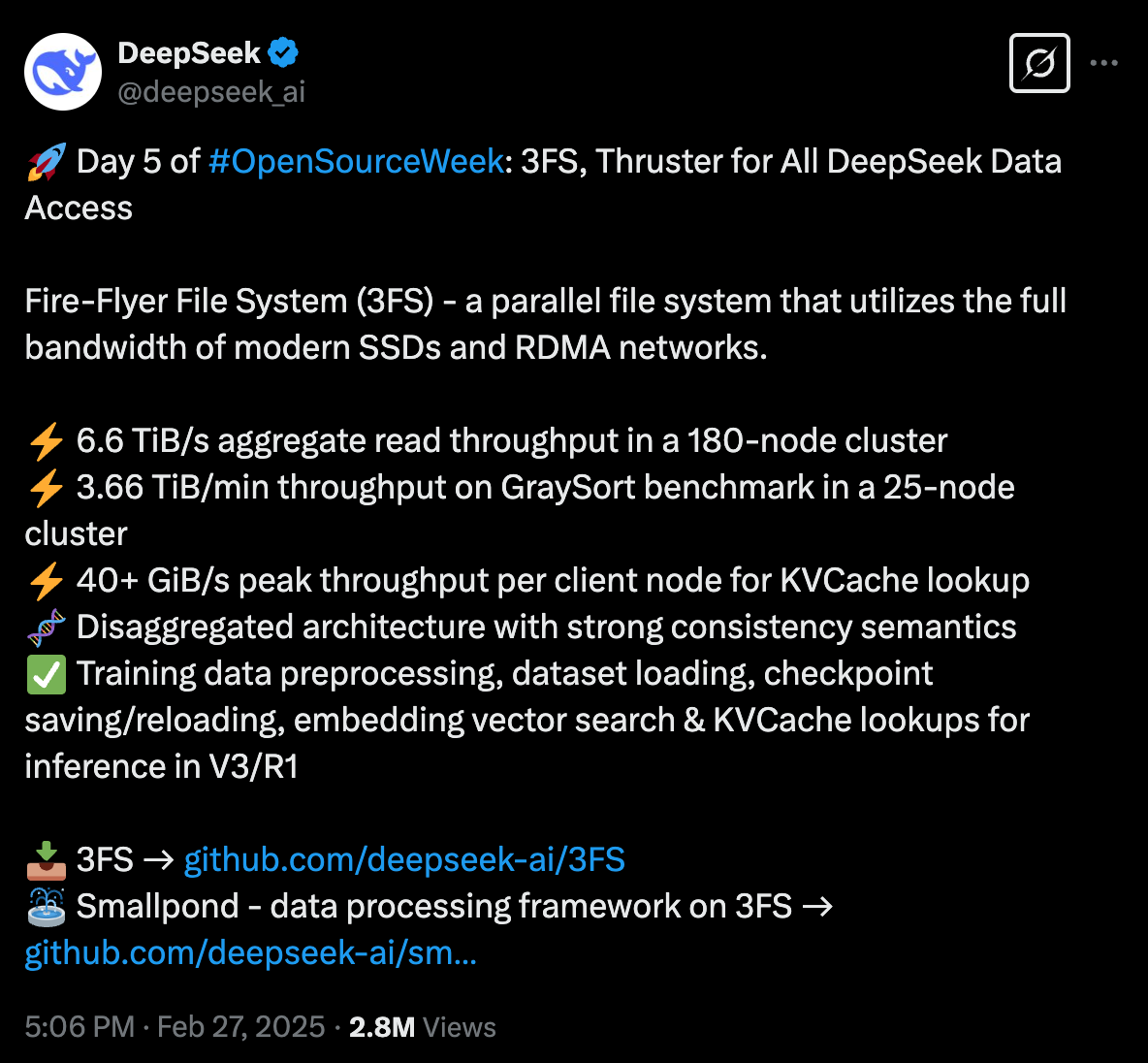
The bombshell DeepSeek tweet in question with 2.8M views!
3FS is a distributed filesystem Distributed filesystems are run on a cluster of high-performance storage machines. To access them, other machines (“compute nodes”) mount a network-attached filesystem via a FUSE mount so that all processes running on the compute node will see the 3FS filesystem as “just another folder” on disk that it can read files from/write files to.
Note that 3FS runs on machines with really expensive/complex networking and NVMe SSDs. This doesn’t run on run-of-the-mill cloud machines.
The storage nodes for 3FS are described as each having 2×200Gbps InfiniBand NICs and 16×14TiB NVMe SSDs. That’s a LOT of really high performance storage and networking which usually requires experts to bring up and properly configure.
This is specialized hardware, for specialized use-cases: AI model training, inference and KVCaches for large language models.
smallpond is a distributed data engine that runs on top of 3FS Internally, smallpond uses DuckDB as its local execution engine. 3FS is used here both as storage, but also for handling intermediate data during datashuffles. This means that every machine you run smallpond on needs to have FUSE mount access to the aforementioned 3FS cluster.
Similar to 3FS, smallpond is designed to run on a cluster of high-performance computing hardware, with each machine having 192 physical cores, 2.2 TiB RAM, and 1×200 Gbps NIC/node in the GraySort benchmark that was presented.
Benchmarks/use-cases that don’t actually reproduce the high-performance computing environments that 3FS and smallpond are built to run on won’t be able to showcase the intended use-case of these systems. Running smallpond on your laptop for example is a horrible example of what this system is actually built to do.
DeepSeek likely built this software because they already have a high-performance computing (HPC) environment with dedicated hardware and datacenters, built around their research team for high-frequency trading (HFT). Systems such as SLURM and 3FS are common in HPC environments for the types of work that researchers do on supercomputers (see: Frontier supercomputer).
Is this architecture novel?
No it is not! Here’s the good old MapReduce from the legendary Jeff Dean and Sanjay Ghemawat at Google — one of the original “Big Data” papers.
MapReduce architecture diagram
“MapReduce reads its input from and writes its output to the Google File System”
Google’s MapReduce architecture has workers reading and writing from a distributed filesystem (Google File System and later its successor, Colossus). Sound familiar? That’s is a very similar architecture to smallpond + 3FS — it’s really an implementation of MapReduce!
Here are some of the main differences/choices made by the developers of smallpond:
For computations, the engine it uses is pretty fungible — here’s a test-case in the codebase that tests it against a host of different execution engines.
The API supports using DuckDB, Python or PyArrow which run on single rows or batches of rows (see: DataFrame.map and DataFrame.map_batches). You can technically run any engine that accepts Arrow data (e.g. even daft would work!)
The distributed filesystem 3FS is used for both data storage as well as intermediate data during shuffles (see: DataFrame.repartition).
Note that MapReduce has optimizations for writing intermediate shuffle data to local disk on compute nodes rather than relying on the distributed filesystem for shuffles. It doesn’t seem like smallpond does anything like this.
The smallpond API is fairly low-level. For example, to perform a join between two dataframes, it suggests running the following sequence of code, which is a hash join in MapReduce form.
a = sp.read_parquet("a/*.parquet").repartition(10, hash_by="id")
b = sp.read_parquet("b/*.parquet").repartition(10, hash_by="id")
c = sp.partial_sql("select * from {0} join {1} on a.id = b.id", a, b)
Modern data engines such as daft support a higher level SQL-like API (see: daft.DataFrame.join) that abstracts these details away from the user, often employing optimizations where appropriate to speed things up.
It seems likely that users of smallpond at DeepSeek don’t particularly care — they want as low level of control as possible and eschew the high level abstractions of SQL semantics.
How impressive are the numbers presented here, really?
The GraySort benchmark presented by DeepSeek has a leaderboard maintained on https://sortbenchmark.org.
Definition of GraySort from sortbenchmark.org
Let’s examine a system that most in the data processing space are familiar with — Apache Spark.
11 years ago in 2014, Spark took the crown for GraySort with a 100TB shuffles in 23 minutes. Let’s compare this with the results presented by smallpond + 3FS.
Apache Spark (2014) 23 minutes to sort 100TiB of data
Machines: 207 i2.8xlarge AWS machines
Hardware: 6,624 CPUs / 50TiBRAM
Networking (commodity): 10 Gibps of non-EFA networking per node
smallpond + 3FS (2025) 30 minutes to sort 110.5TiB of data
Networking (HPC): 200-800 Gibps of Infiniband networking per node
This old version of Apache Spark actually performs much better than smallpond + 3FS, using easily available cloud hardware and a fraction of the amount of hardware for this sorting workload. Viewed from this perspective, smallpond + 3FS performance isn’t particularly groundbreaking.
So if performance isn’t the main reason, why did DeepSeek invest in their own distributed filesystem/data processing tool?
Are AI data workloads special?
AI/ML Data Tools
When building the daft data engine, we wanted to stick to a core set of principles that are key to building data tools for AI/ML.
Python-first: AI developers today primarily interface with data using Python and its associated ecosystem (Pytorch, Numpy, OpenAI SDK etc)
Best-in-class local development user experience: AI/ML researchers all start by iterating and experimenting first on a single machine — not a cluster
Multimodal data and workloads: support for datatypes such as images, HTML and embeddings — but also common workloads such as LLM model inference
As a data engine, `smallpond` is a step in this direction — it’s a Python library, uses DuckDB (which is one of the best local data execution engines in open source) and allows users to run arbitrary Python functions which helps for multimodal data. It also allows scheduling functions over GPUs which is obviously a big requirement for AI/multimodal work!
On the other hand, it still has a pretty strong dependency on being a cluster-first framework (you need 3FS for this to really work…) and the API isn’t a general-purpose ETL tool that can seamlessly replace your current data stack.
AI/ML Data Workloads
However — many AI data processing workloads aren’t general purpose! Workloads such as semantic deduplication, clustering and model batch inference are often some combination of:
read → repartition → map_partitions → … → write
This is easily expressible via the smallpond API, and grants users a lot of low-level control because the intermediate logic can be expressed as Python functions/DuckDB.
Zooming out beyond just data processing — the 3FS filesystem excels at workloads with random access data access patterns. Other distributed filesystems such as Lustre struggle with this.
Non-data processing AI use-cases include model training (dataloading, checkpointing) and model inference (KVCaches).
However specifically for data processing, access patterns are often predictable — full scans of entire partitions during scans or shuffles.
This means that 3FS as a necessary dependency can actually hurt performance (as we saw in the comparison against Spark’s GraySort benchmarks) rather than help it.
Realistically, should I be using smallpond/3FS?
If you are a company with the necessary HPC hardware (e.g. AI labs, academic labs or high-frequency trading) 3FS could be an interesting option to explore. This is especially true if you are working with workloads that require a lot of random access pattens. Note that this is a significant investment in building and operating your own 3FS cluster.
And if you already have 3FS, then smallpond is an interesting option to explore as a lightweight data processing utility on top of this really powerful distributed filesystem!
The smallpond/3fs systems are extremely solid and well designed systems. But they are specialized tools for specialized use-cases that only work on specialized hardware.
For data analytics and engineering workloads, folks are still better off running tools like Spark, Trino, DuckDB and Daft. We also believe that also for running AI workloads, most folks will be better off running Daft which is designed from the ground up for these workloads:
High performance Rust kernels for reading/writing from cloud storage data in table catalogs and formats such as Apache Iceberg/Delta Lake/Parquet or even more dedicated file formats such as WARC for CommonCrawl data
Delightful UX on your local machine (without a dependency on a cluster!) but also runs on a cluster of readily available cloud machines such as AWS EC2
Thanks for reading Daft Engineering Blog! Subscribe for free to receive new posts and support our team’s work!







Great context on what use cases Smallpond is best for!