
From v0.2 to v0.3: Harder, Better, Faster, Stronger
Join us on the journey from Daft v0.2 to v0.3!


Daft v0.3 was released last month, marking the first minor version increment in almost 10 months. Let’s take a look at some of the ways Daft has grown in this release, and what you can expect from us looking forward.
The journey from v0.2 to v0.3 involved 636 commits from 41 unique contributors. Along the way, we also grew by more than 1k GitHub Stars! Thank you to the Daft community who have been supporting us throughout this journey.
Feature Highlights
We’ve added numerous new features—here are some of our top picks.
Enhanced Data Source Support
Daft v0.2 was a big version for data connectivity. The formats Daft can natively read from now include:
The most commonly used SQL databases
In addition, we now support several more ways to write out a DataFrame, including to Iceberg, Delta Lake, and Lance tables, as well as Hive-style partitioned writes.
Read about how we worked with the Delta Lake team to build one of the fastest Delta Lake readers.

Full Join Type Coverage
Daft now has the complete suite of join operations available, including left, right, outer, anti, and semi joins. This means we now have full coverage of all 22 questions in the TPC-H test suite.
Daft-SQL
In May, we introduced early support for running SQL queries in Daft. In addition to writing queries with daft.sql(), you can also write SQL within your DataFrame operations, such as in the following example:
df.where("score > 0").select(custom_udf("text"))
We are continuing to make progress on SQL support; you can learn more about it in our recently released blog post.
And More…
In v0.3, we’ve also added support for all of the following:
Dozens of new expressions, such as MinHash, bitwise, and trigonometry expressions
A new way to visualize query plans with
DataFrame.explain
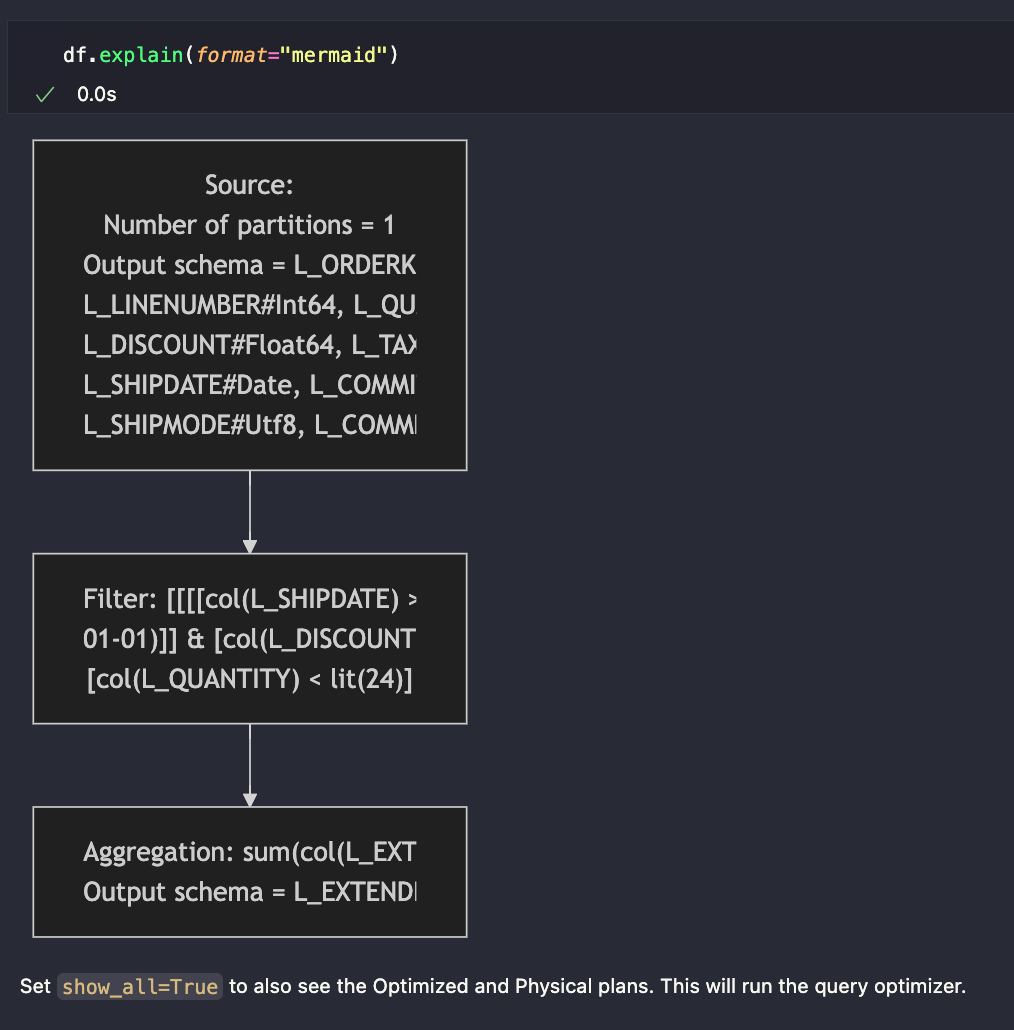
See the full changelog here.
Performance Highlights
Our goal is to make Daft the fastest distributed query engine, and we’re making great strides. Here are some of the recent steps we’ve taken toward making that goal a reality!
Faster File Reads
We’ve made large performance improvements to file reads, particularly for CSV and Parquet.
CSV
Daft now has a streaming and parallel reader that takes advantage of SIMD operations and is more than 4x faster than PyArrow’s CSV reader. We also added support for predicate pushdowns so that only the necessary columns are read from a file.
Looking forward to v0.4, we’re working on shipping an even faster CSV reader that uses speculative parsing!
Parquet
We built our own Rust-based filesystem Parquet reader and added support for predicate pushdowns, similar to CSV reads. In addition, with its ability to parallelize reads by Parquet row group, Daft is currently the most flexible query engine for reading large Parquet files.
Head over to our blog post to learn more about why it’s so good at reading files of all different sizes.
New Join Strategies
In addition to more join types, we’ve also made joins in general faster with some new join strategies:
Broadcast join combines the smaller side of the join into one partition and joins that with each of the partitions on the larger side, eliminating the need to fully materialize and shuffle a large table.
Sort-merge join takes advantage of the sort order of two tables to zip up partitions efficiently into a sorted table. This is advantageous if you already have two tables that are sorted, or if you need to join as well as sort, since this operation does both at the same time!
Our users have already observed significant performance improvements using these new strategies. For instance, Together AI, a research-driven artificial intelligence company, achieved a 20% speed boost by using broadcast anti-joins in their document deduplication workflow, while also eliminating a complex hand-written query.
Streaming Execution
We recently introduced an experimental push-based streaming executor (codename Swordfish). This will replace Daft’s current partitioned pull-based execution engine. The new executor will succeed Daft’s local runner in the v0.4 release and then Daft’s distributed engine in v0.5.
Swordfish has already proven to significantly improve execution performance while also dramatically reducing memory usage. Below are some preliminary results on TPC-H performance with Swordfish.

Check out our August Deep Dive to learn more about Project Swordfish behind the scenes! It’s currently in its final phases of completion.
What’s Next?
We’ve talked about the major improvements from v0.2 to v0.3, but what about v0.4, v0.5, and beyond? Here’s a peek at what’s in the pipeline!
v0.4
Stabilizing the Streaming Engine
In v0.4, we will enable the push-based streaming executor as the default engine when running Daft on your local machine. We’re aiming for faster performance in all our benchmarks while also having a lower memory footprint. This will enable our users to have DuckDB-level local performance, with no changes required to their existing Daft queries.
First-Class SQL Support
Daft will also have much richer SQL support in the next release. We expect to have Daft expression parity in SQL, meaning any expression you can use via the DataFrame API will also be usable in SQL.
Keep up with our progress on SQL in this GitHub project!
Distributed Push-Based Shuffler
As our users have been pushing Daft to larger and larger workloads, they have been asking us to improve performance when it comes to joins, grouped aggregations, and sorts at the 100+ terabyte scale. Push-based shuffling will enable Daft to process data an order of magnitude larger than what currently is possible.
Improved Batch Inference
We’ve been improving the UX around running models on GPUs in Daft, with the aim of ensuring users have total control over the number of running models, batch sizing, and GPUs to allocate to models. These features are currently in beta and will become the defaults in 0.4.
Daft Launcher
If your organization maintains a Ray cluster, running distributed Daft is seamless. However, users who do not have an existing cluster have been looking for an easier way to test out Daft in distributed mode.
That’s why we’re working on releasing Daft Launcher, an open source command-line tool that will provide easy cluster management for Daft. Using Daft Launcher, you can spin up clusters on AWS, GCP, and (coming soon) Azure, with a simple command.
Here’s a sneak peek at what it looks like today:
➜ daft --help
Usage: daft [OPTIONS] COMMAND [ARGS]...
A simple launcher for spinning up and managing Ray clusters for Daft.
Commands:
dashboard Enable port-forwarding between a cluster & your local...
down Spin the cluster down.
init-config Create a new configuration file.
list List all running clusters.
submit Submit a job to the specified cluster.
up Spin the cluster up.v0.5
Distributed Streaming Engine
We plan to enable our push-based streaming executor for local execution in v0.4, but what about distributed workloads? In v0.5, we’ll bring streaming execution to our distributed engine, which will provide significant speed and memory improvements to all distributed queries.
If you’d like to stay in the know about the latest Daft developments, tune in to our next Daft Monthly Contributor Sync, on the last Thursday of every month. You can also find us on GitHub or join our Distributed Data Community Slack — we always welcome feedback and are eager to learn more about your workloads!
Daft is the best to read iceberg tables
Looking forward to SQL announcements