

The challenges of processing multimodal data, including images, embeddings, and nested structures, have always posed a significant hurdle for developers, who typically have to trade off between performance, features, and ergonomics.
We built Daft to be a game-changer, providing an efficient solution for handling multimodal data by leveraging the power of Rust and the Arrow format while still being Pythonic!
So, what is it?
Daft is a distributed dataframe library that brings familiarity to developers already acquainted with pandas or polars.
However, Daft goes beyond the capabilities of traditional dataframe libraries by offering additional benefits:
Distributed: Daft seamlessly works on both a laptop and a massive cloud cluster, enabling processing power at varying scales by leveraging the Ray framework.
Complex Types: Native support for complex types and memory formats, such as images, allowing for efficient handling and processing.
Rust Compute Engine: By utilizing Rust, Daft maximizes the performance potential of modern hardware, including SIMD optimizations.
Smart Memory Management: Daft optimizes memory usage, enabling small clusters to handle large datasets efficiently.
Out-of-Core Processing: Daft's ability to process data larger than the available memory empowers users to work with datasets of any size.
What does it look like?
Daft empowers developers to work with diverse data types from a variety of sources within a unified framework.
For example, let's say you wanted to load some images from S3 cloud storage:
df = (daft
.from_glob_path('s3://...')
.into_partitions(8)
.with_column('image', col('path').url.download().image.decode()))Let’s unpack what Daft does here:
daft.from_glob_path(s3://...): Daft pattern matches the S3 bucket for image files and yields a lazy dataframe of just the metadata..into_partitions(n): Daft splits our dataframe into partitions, which allows us to chunk up our data, enabling parallel processing and larger than core-memory workloads..with_column(‘image’, col(“path”).url.download().image.decode()): This step adds a new column named 'image' by downloading the images from the URLs in the 'path' column and decoding them directly into contiguous memory.
Daft makes this easy by providing a type system for common complex types, such as images and embeddings, as well as deeply nested types found in JSONs and protobufs.
Check out our tutorials to learn more:
A full list of supported types can be found in our documentation.
How well does it work?
Here we compare Daft against some popular distributed dataframes such as Spark, Modin, and Dask on the TPC-H benchmark.
Our goals for this benchmark is to demonstrate that Daft is able to meet the following development goals:
Solid out of the box performance: great performance without having to tune esoteric flags or configurations specific to this workload
Reliable out-of-core execution: highly performant and reliable processing on larger-than-memory datasets, without developer intervention and Out-Of-Memory (OOM) errors
Ease of use: getting up and running should be easy on cloud infrastructure for an individual developer or in an enterprise cloud setting
A great stress test for Daft is the TPC-H benchmark, which is a standard benchmark for analytical query engines. This benchmark helps ensure that while Daft makes it very easy to work with multimodal data, it can also do a great job at larger scales (terabytes) of more traditional tabular analytical workloads
Highlights
Out of all the benchmarked frameworks, only Daft and EMR Spark are able to run terabyte scale queries reliably on out-of-the-box configurations.
Daft is consistently much faster (3.3x faster than EMR Spark, 7.7x faster than Dask dataframes, and 44.4x faster than Modin).
TPCH 100 Scale Factor
First we run TPC-H 100 Scale Factor (around 100GB) benchmark on 4 i3.2xlarge worker instances. In total, these instances add up to 244GB of cluster memory which will require the dataframe library to perform disk spilling and out-of-core processing for certain questions that have a large join or sort.

From the results we see that Daft, Spark, and Dask are able to complete all the questions and Modin completes half. We also see that Daft is 3.3x faster than Spark, 7.7x faster than Dask, and 44.4x faster than Modin (for questions that completed). We expect these speed-ups to be much larger if the data is loaded in memory instead of cloud storage, which we will show in future benchmarks.
TPCH 1000 Scale Factor
Next we scale up the data size by 10x while keeping the cluster size the same. Since we only have 244GB of memory and 1TB+ of tabular data, the dataframe library will be required to perform disk spilling and out-of-core processing for all questions at nearly all stages of the query.
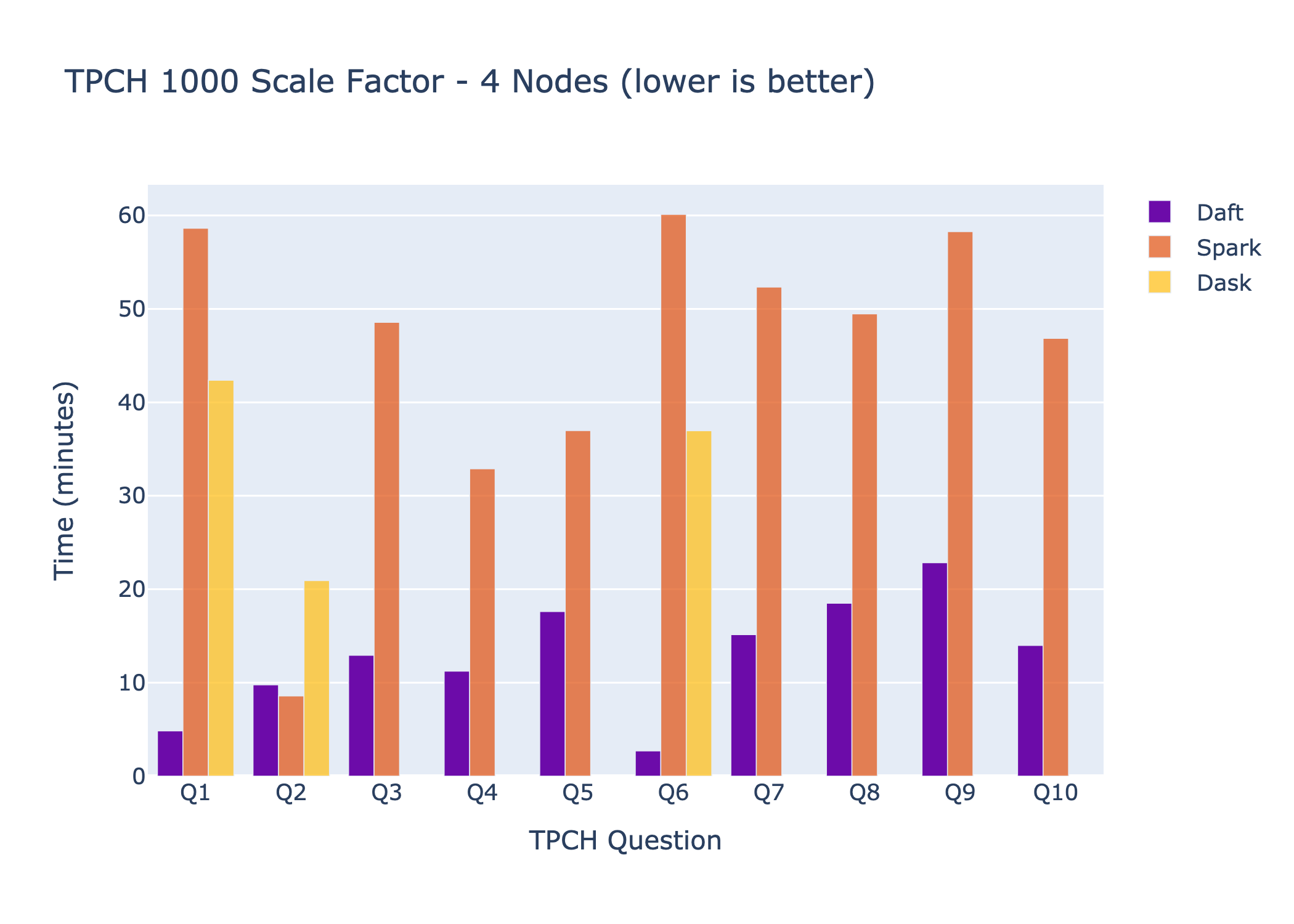
From the results we see that only Daft and Spark are able to complete all the questions. Dask completes less than a third and Modin is unable to complete any due to OOMs and cluster crashes. We see that Daft is 3.5x faster than Spark and 5.8x times faster than Dask (for questions that completed). This shows that Daft and Spark are the only dataframes in this comparison capable of processing data larger than memory, with Daft standing out as the significantly faster option.
Finally, we compare how Daft performs on varying size clusters on the terabyte scale dataset. We run the same Daft TPC-H questions on the same 1TB dataset but sweep the worker node count.
TPCH 1000 - Node Count Ablation

We note two interesting results here:
Daft can process 1TB+ of analytical data on a single 61GB instance without being distributed (16x more data than memory).
Daft query times scale linearly with the number of nodes (e.g. 4 nodes being 4 times faster than a single node). This allows for faster queries while maintaining the same compute cost!
Detailed Setup
To see the complete benchmarks and detailed setup, checkout our benchmarking page in our docs.
To explore the code used to set up the clusters and run the queries, check out our open-source benchmarking repo! The repository contains all the necessary scripts, configs, and logs for full reproducibility.
Wrapping up
In the upcoming weeks, we'll be sharing even more details about Daft's architecture, performance benchmarks, and use cases. Stay tuned to learn more about how Daft can supercharge your multimodal data processing tasks!
To get started with Daft, visit our GitHub repository and explore our comprehensive documentation and tutorials! You can also join our distributed data processing Slack Group!
Let's unlock the full potential of your multimodal data and get Daft together!
-Sammy
Hey Sammy, great post!
I am running a Discord community for practitioners tinkering with Multimodal AI research and applications.
Would love to have you join and share Daft with our members: https://discord.com/invite/Sh6BRfakJa
The links to tutorials are broken
```
Check out our tutorials to learn more:
Running LLMs on the Red Pajamas Dataset
Querying Images with UDFs
DALL-E Image generation on GPUs
```
Can we please have them fixed.