
We cloned over 15,000 repos to find the best developers
An adventure in AI and data engineering to analyze developers across Github

Using Daft, a distributed Python data engine, we built a comprehensive dataset of the top GitHub developers, evaluated by their contributions. We analyzed over 30 million commits across more than 15,000 repositories, all in the span of two days. This complex project—combining data engineering, batch inference, and analytics—was made easy using Daft.
Ever wonder who the best open source developers are?
My first guess would be the ones with anime profile pictures and READMEs loaded with their Github stats:
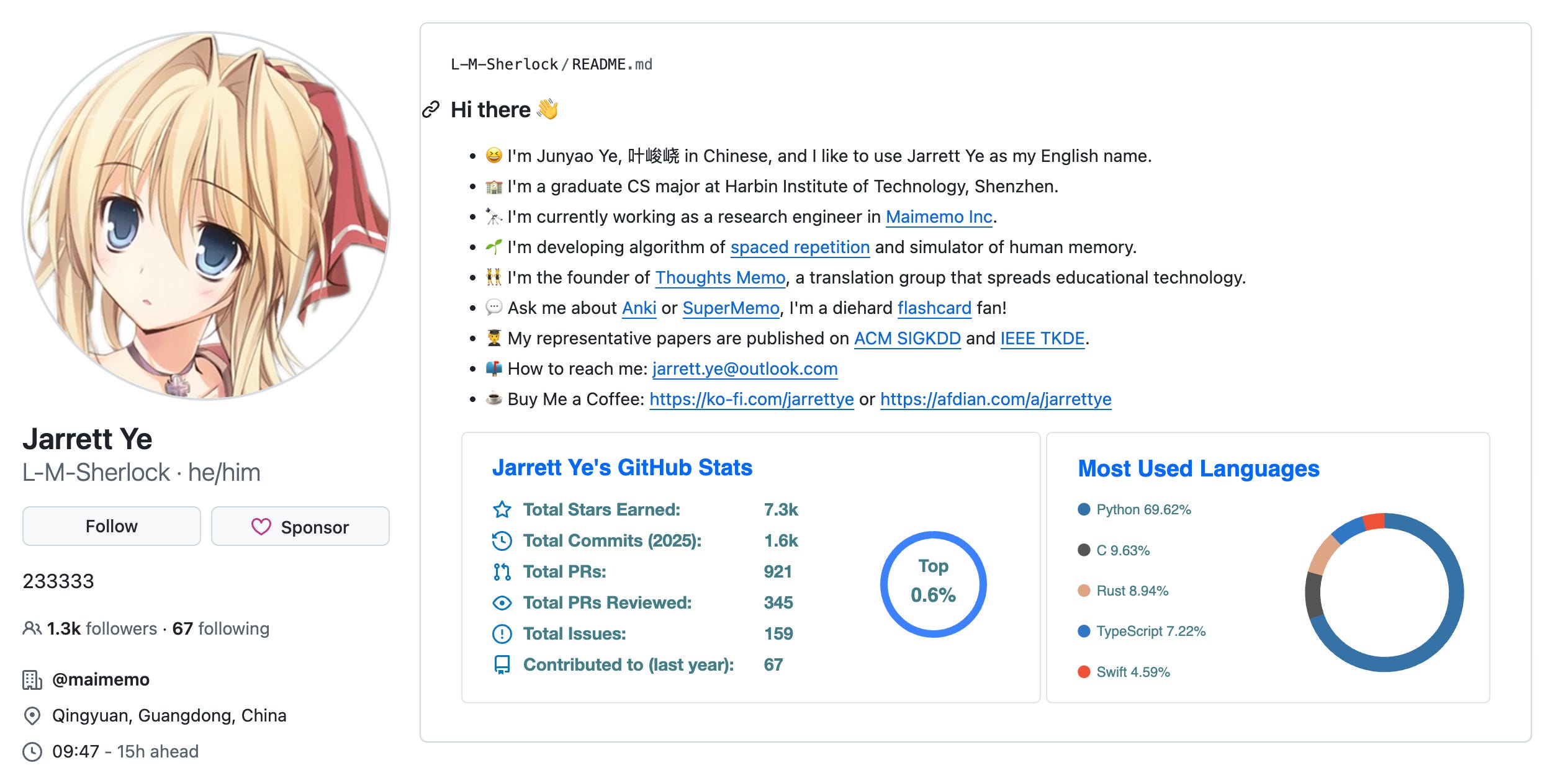
But does a stacked GitHub profile always translate to coding ability? Personally, I believe quality beats quantity, and a naive GitHub search to find developers with the most commits ain’t gonna cut it. I wanted to look into the commits themselves, the files changed, the review comments.
So, I did what any reasonable person nowadays would do. Clone a repo, and dump the git log into ChatGPT, and ask it to rank each contributor based on their commits. (A gross oversimplification, but I’ll get to the details in a bit)
In only 2 days, we cloned over 15,000 repositories, analyzed over 33 million commits, and created a dataset of over 250,000 contributors ranked by their commits. Plus, we hosted it on a website called sashimi4talent.com with an AI generated fish on it (for context, we developed this during an internal hackathon with an omakase dinner as the prize, hence the fish and the website name).
How we built it: From GitHub to developer database
For this project, we used Daft, a distributed python data engine.
What makes Daft special is its ability to handle both traditional analytics (think Spark or Pandas) and arbitrary Python operations through User-Defined Functions (UDFs). Daft scales from your laptop to a cluster without breaking a sweat.
This was great because we had to make API calls to Github and OpenAI, custom string parsing for the git commits, and traditional data transformations like group-by aggregations and joins. Daft’s flexibility was critical for this project.
Phase 1: Finding Repositories
The first challenge was finding the repositories we wanted to analyze. We used the PyGithub library to search for the top starred repos across languages, and ended up with a list of around 15,000 repos.
| # Search GitHub API for repos using a Daft UDF and write the results. | |
| def find_github_repos(query): | |
| res = [] | |
| repos = github.search_repositories(query=query, sort="stars", order="desc") | |
| for repo in repos: | |
| res.append( | |
| { | |
| "name": repo.name, | |
| "owner": repo.owner.login, | |
| } | |
| ) | |
| return res | |
| queries = ["language:python", "language:rust", "language:javascript", "language:go"] | |
| languages = daft.from_pydict({"queries": queries}).with_column( | |
| "repos", | |
| # Apply the UDF on the query column | |
| daft.col("queries").apply( | |
| find_github_repos, | |
| return_dtype=daft.DataType.struct( | |
| { | |
| "name": daft.DataType.string(), | |
| "owner": daft.DataType.string(), | |
| } | |
| ), | |
| ), | |
| ) | |
| languages.show() | |
| languages.write_parquet("repos") |
It was super easy to use Daft’s DataFrame API to structure the steps of the workflow. I was able to drop in a plain old python function into Daft as a UDF, and chain it with a write_parquet method to persist all the results to a file for later use. Here’s a sample of what the data looks like:
| ╭────────────────────────┬──────────────────────┬───────────────────────────────┬──────────────────────────────┬────────┬───────────────────────────┬───────────────────────────╮ | |
| │ name ┆ owner ┆ url ┆ description ┆ stars ┆ updated ┆ created_at │ | |
| │ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │ | |
| │ Utf8 ┆ Utf8 ┆ Utf8 ┆ Utf8 ┆ Int64 ┆ Utf8 ┆ Utf8 │ | |
| ╞════════════════════════╪══════════════════════╪═══════════════════════════════╪══════════════════════════════╪════════╪═══════════════════════════╪═══════════════════════════╡ | |
| │ public-apis ┆ public-apis ┆ https://github.com/public-api ┆ A collective list of free ┆ 335606 ┆ 2025-04-14 17:04:02+00:00 ┆ 2016-03-20 23:49:42+00:00 │ | |
| │ ┆ ┆ … ┆ API… ┆ ┆ ┆ │ | |
| ├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤ | |
| │ system-design-primer ┆ donnemartin ┆ https://github.com/donnemarti ┆ Learn how to design ┆ 296332 ┆ 2025-04-14 17:04:58+00:00 ┆ 2017-02-26 16:15:28+00:00 │ | |
| │ ┆ ┆ … ┆ large-sca… ┆ ┆ ┆ │ | |
| ├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤ | |
| │ awesome-python ┆ vinta ┆ https://github.com/vinta/awes ┆ An opinionated list of ┆ 240376 ┆ 2025-04-14 16:57:13+00:00 ┆ 2014-06-27 21:00:06+00:00 │ | |
| │ ┆ ┆ … ┆ awesom… ┆ ┆ ┆ │ | |
| ├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤ | |
| │ Python ┆ TheAlgorithms ┆ https://github.com/TheAlgorit ┆ All Algorithms implemented ┆ 199406 ┆ 2025-04-14 16:33:32+00:00 ┆ 2016-07-16 09:44:01+00:00 │ | |
| │ ┆ ┆ … ┆ in… ┆ ┆ ┆ │ | |
| ├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤ | |
| │ AutoGPT ┆ Significant-Gravitas ┆ https://github.com/Significan ┆ AutoGPT is the vision of ┆ 174431 ┆ 2025-04-14 15:25:19+00:00 ┆ 2023-03-16 09:21:07+00:00 │ | |
| │ ┆ ┆ … ┆ acce… ┆ ┆ ┆ │ | |
| ├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤ | |
| │ stable-diffusion-webui ┆ AUTOMATIC1111 ┆ https://github.com/AUTOMATIC1 ┆ Stable Diffusion web UI ┆ 151202 ┆ 2025-04-14 17:01:37+00:00 ┆ 2022-08-22 14:05:26+00:00 │ | |
| │ ┆ ┆ … ┆ ┆ ┆ ┆ │ | |
| ├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤ | |
| │ transformers ┆ huggingface ┆ https://github.com/huggingfac ┆ 🤗 Transformers: ┆ 142939 ┆ 2025-04-14 16:25:48+00:00 ┆ 2018-10-29 13:56:00+00:00 │ | |
| │ ┆ ┆ … ┆ State-of-the-… ┆ ┆ ┆ │ | |
| ├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤ | |
| │ youtube-dl ┆ ytdl-org ┆ https://github.com/ytdl-org/y ┆ Command-line program to ┆ 135112 ┆ 2025-04-14 16:57:22+00:00 ┆ 2010-10-31 14:35:07+00:00 │ | |
| │ ┆ ┆ … ┆ downl… ┆ ┆ ┆ │ | |
| ╰────────────────────────┴──────────────────────┴───────────────────────────────┴──────────────────────────────┴────────┴───────────────────────────┴───────────────────────────╯ | |
| (Showing first 8 rows) |
Phase 2: Extracting Commits at Scale
Now that we have a list of repos, we needed to extract the commits for all the contributors. Since we were already using PyGithub, our initial idea was to retrieve commits via the get_commits API. However, we were quickly hit hard by GitHub’s rate limits. 🥴 I mean, just look at Chromium for example, over 1.5 million commits!
With limited time and an omakase dinner on the line, we decided to go old school. Clone the repo, and manually parse the commits ourselves.
With over 15,000 repos to clone and who knows how many commits there were going to be (spoiler alert, over 30 million), there was no way I could do this locally on my laptop.
For doing work at large scale, I had to go distributed. Easily enough, Daft has integrations with Ray, a library that makes distribution easy. All I needed to do was point Daft to a Ray cluster, and let it do it’s thing.
| # Configure Daft to use a Ray cluster | |
| daft.set_runner_ray(address="ray://my-cluster:10001") | |
| def extract_commits_from_logs(logs): | |
| ... | |
| # Clone repos and extract commits in parallel | |
| @daft.udf(return_type=...) | |
| def clone_and_extract_commits(repo_urls): | |
| parsed_logs = [] | |
| for repo_url in repo_urls: | |
| with tempfile.TemporaryDirectory() as temp_dir: | |
| # Clone the repo | |
| repo = git.Repo.clone_from( | |
| repo_url, to_path=temp_dir, multi_options=["--no-checkout"] | |
| ) | |
| # Get git logs | |
| logs = repo.git.log( | |
| "--pretty=format:---COMMIT START---%n%H%n%an%n%ae%n%ai%n%B%n---COMMIT END---", | |
| "--date=iso", | |
| "--numstat", | |
| ) | |
| # Extract commits from logs | |
| commits = extract_commits_from_logs(logs) | |
| parsed_logs.extend(commits) | |
| return parsed_logs | |
| # UDFs | |
| df = df.with_column("commits", clone_and_extract_commits(df["repo_url"])) | |
| df.write_parquet("commits") |
The same code works regardless of running locally vs in a remote cluster. Under the hood, Daft intelligently schedules work to make use of all available resources.
With the power of infinite compute (until I hit my vCPU limit), I was able to finish extracting all 33 million commits in half an hour. Had I stuck to using GitHub’s rate limited API on a single laptop, this probably would have taken days.
(Fun fact, a lot of the processing time actually came from extracting the big boy repos, like React, or for some reason, the AWS Java SDK)
Phase 3: Grouping contributors and repos (and some good old deduping)
Now that we had all these commits, we wanted to group them by contributor and repo.
Grouping and aggregating is really easy with Daft’s traditional DataFrame API. Aside from simple arithmetic aggregates like sum, min, and max, you can also aggregate values into a list via agg_concat, or just take any value from the group via any_value.
| df = df.groupby("repo_owner", "repo_name", "author_email").agg( | |
| [ | |
| daft.col("author_name").any_value(), | |
| daft.col("date").count().alias("commit_count"), | |
| daft.col("lines_added").sum(), | |
| daft.col("lines_deleted").sum(), | |
| daft.col("lines_modified").sum(), | |
| daft.col("files_changed").agg_concat(), | |
| daft.col("message").agg_concat(), | |
| daft.col("date").min().alias("first_commit"), | |
| daft.col("date").max().alias("last_commit"), | |
| ] | |
| ) | |
| df.write_parquet('grouped_contributors') |
Alright! Let’s see some of these contributors. Why not start with the creator of Daft himself!
| df = daft.read_parquet('grouped_contributors') | |
| df = df.where((df['author_name'] == 'Sammy Sidhu') & (df['repo_name'] == 'Daft')) | |
| df.show() | |
| ╭──────────────┬───────────┬─────────────────────┬─────────────┬──────────────┬────────────┬─────────────────────┬────────────────────┬────────────────────┬────────────────────╮ | |
| │ repo_owner ┆ repo_name ┆ author_email ┆ author_name ┆ commit_count ┆ … ┆ files_changed ┆ message ┆ first_commit ┆ last_commit │ | |
| │ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ ┆ --- ┆ --- ┆ --- ┆ --- │ | |
| │ Utf8 ┆ Utf8 ┆ Utf8 ┆ Utf8 ┆ UInt64 ┆ (3 hidden) ┆ List[Utf8] ┆ Utf8 ┆ Timestamp(Millisec ┆ Timestamp(Millisec │ | |
| │ ┆ ┆ ┆ ┆ ┆ ┆ ┆ ┆ onds, None) ┆ onds, None) │ | |
| ╞══════════════╪═══════════╪═════════════════════╪═════════════╪══════════════╪════════════╪═════════════════════╪════════════════════╪════════════════════╪════════════════════╡ | |
| │ Eventual-Inc ┆ Daft ┆ sammy@eventualcompu ┆ Sammy Sidhu ┆ 6 ┆ … ┆ [tests/test_datacla ┆ add dict for root ┆ 2022-06-10 ┆ 2022-06-17 │ | |
| │ ┆ ┆ ting.com ┆ ┆ ┆ ┆ sses.py, d… ┆ types ┆ 02:02:32 ┆ 23:46:48 │ | |
| │ ┆ ┆ ┆ ┆ ┆ ┆ ┆ creat… ┆ ┆ │ | |
| ├╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤ | |
| │ Eventual-Inc ┆ Daft ┆ sammy.sidhu@gmail.c ┆ Sammy Sidhu ┆ 83 ┆ … ┆ [daft/schema.py, ┆ missed these files ┆ 2022-05-10 ┆ 2022-07-14 │ | |
| │ ┆ ┆ om ┆ ┆ ┆ ┆ tests/test_s… ┆ in pre-com… ┆ 20:17:33 ┆ 00:59:31 │ | |
| ├╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤ | |
| │ Eventual-Inc ┆ Daft ┆ samster25@users.nor ┆ Sammy Sidhu ┆ 461 ┆ … ┆ [Cargo.lock, ┆ [PERF] ┆ 2022-05-14 ┆ 2025-03-02 │ | |
| │ ┆ ┆ eply.githu… ┆ ┆ ┆ ┆ Cargo.toml, src/… ┆ Micropartition, ┆ 00:04:51 ┆ 22:06:33 │ | |
| │ ┆ ┆ ┆ ┆ ┆ ┆ ┆ lazy l… ┆ ┆ │ | |
| ╰──────────────┴───────────┴─────────────────────┴─────────────┴──────────────┴────────────┴─────────────────────┴────────────────────┴────────────────────┴────────────────────╯ |
Wait a minute, there’s three of them?? Turns out, the same contributor could have multiple emails, so grouping by just email wasn’t the best solution. We had to subsequently dedupe the contributor data by grouping on name as well. This way, we can collect all emails per contributor as well.
| deduped = df.groupby("repo_owner", "repo_name", "author_name").agg( | |
| [ | |
| col('author_email').agg_list(), | |
| col('commit_count').sum(), | |
| col('lines_added').sum(), | |
| col('lines_deleted').sum(), | |
| col('lines_modified').sum(), | |
| daft.col("message").agg_concat(), | |
| col('first_commit').min(), | |
| col('last_commit').max(), | |
| ] | |
| ) |
Of course, what if someone uses a different email and a different name? This was quite a tricky problem, but unfortunately, our hackathon time was running short. 😅
At the end of the day, we ended up with around 250,000 contributors, ready to be scored.
Phase 4: AI inference
With these grouped and deduped contributors, it was finally time to let the AI take over. Our plan was to pass in a full list of a contributors commits, and have the AI judge the contributor for us.
To ensure quality determinations, we needed to give it as much context as possible. We provided it with all their commit messages, the names of the files they changed, and general commit statistics like lines added / deleted.
Here’s an example prompt:
You are an expert at analyzing GitHub contributions and determining developer impact and technical ability.
Analyze the following GitHub contribution data to assess:
1. The contributor's impact to the project (score 1-10):
- 10: Core maintainer/architect whose work is foundational
- 7-9: Major feature owner or frequent substantial contributor
- 4-6: Regular contributor with meaningful additions
- 1-3: Minor/occasional contributor
2. Their technical ability (score 1-10):
- 10: Expert system architect/developer
- 7-9: Very strong technical skills
- 4-6: Competent developer
- 1-3: Beginning developer
Think of Jeff Dean being a 10 and and a script kiddie being a 1. Refer to concrete facts in your rational rather than just giving a high level summary.
Consider:
- Repository: {repo}
- Contribution volume: {c} commits
- Code changes: {la} lines added, {ld} lines deleted, {lm} lines modified
- Scope of changes: Files modified: {f}
Based on these commit messages:
{msg}
Keep your reason explanation brief - maximum 4 sentences.We found that providing a detailed prompt with a clear goal, as well as a strict rubric, produced results in line with our own expectations. For some transparency, we also asked it to provide a reason for the score they came up with.
Here’s a few examples outputs from the LLM:
| ╭────────────────────┬────────────────┬───────────────────┬───────────────────┬──────────────┬────────────────────────────────────────────────────╮ | |
| │ author_name ┆ repo ┆ technical_ability ┆ impact_to_project ┆ commit_count ┆ reason │ | |
| ╞════════════════════╪════════════════╪═══════════════════╪═══════════════════╪══════════════╪════════════════════════════════════════════════════╡ | |
| │ owen leung ┆ PyO3/pyo3 ┆ 8 ┆ 6 ┆ 5 ┆ PyO3/pyo3: The contributor made significant │ | |
| │ ┆ ┆ ┆ ┆ ┆ contributions to the project with 5 commits and │ | |
| │ ┆ ┆ ┆ ┆ ┆ 911 lines modified, affecting various files │ | |
| │ ┆ ┆ ┆ ┆ ┆ including core functionality (src/types/*) and │ | |
| │ ┆ ┆ ┆ ┆ ┆ benchmarks. The scope of changes suggests a good │ | |
| │ ┆ ┆ ┆ ┆ ┆ understanding of the project's architecture and │ | |
| │ ┆ ┆ ┆ ┆ ┆ requirements. The contributor also implemented │ | |
| │ ┆ ┆ ┆ ┆ ┆ several key features (e.g., PartialEq for Pybool │ | |
| │ ┆ ┆ ┆ ┆ ┆ and PyFloat) and optimized existing functionality │ | |
| │ ┆ ┆ ┆ ┆ ┆ (e.g., nth and nth_back for BoundTupleIterator and │ | |
| │ ┆ ┆ ┆ ┆ ┆ BoundListIterator). However, the contributor did │ | |
| │ ┆ ┆ ┆ ┆ ┆ not take on a leadership role or drive major │ | |
| │ ┆ ┆ ┆ ┆ ┆ architectural changes, which prevents a higher │ | |
| │ ┆ ┆ ┆ ┆ ┆ impact score. │ | |
| ├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤ | |
| │ christian ehrhardt ┆ gcc-mirror/gcc ┆ 7 ┆ 5 ┆ 7 ┆ gcc-mirror/gcc: The contributor has made 7 commits │ | |
| │ ┆ ┆ ┆ ┆ ┆ with a moderate volume of code changes (157 lines │ | |
| │ ┆ ┆ ┆ ┆ ┆ added, 37 lines deleted, 194 lines modified). The │ | |
| │ ┆ ┆ ┆ ┆ ┆ scope of changes is broad, touching multiple files │ | |
| │ ┆ ┆ ┆ ┆ ┆ across the project. However, the contributor is │ | |
| │ ┆ ┆ ┆ ┆ ┆ not a maintainer or architect, and the changes are │ | |
| │ ┆ ┆ ┆ ┆ ┆ not entirely foundational. The contributor's │ | |
| │ ┆ ┆ ┆ ┆ ┆ technical ability is strong, with complex │ | |
| │ ┆ ┆ ┆ ┆ ┆ modifications to the compiler's expression and │ | |
| │ ┆ ┆ ┆ ┆ ┆ folding logic. │ | |
| ├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤ | |
| │ agnes tevesz ┆ saltstack/salt ┆ 8 ┆ 7 ┆ 20 ┆ saltstack/salt: The contributor has made a │ | |
| │ ┆ ┆ ┆ ┆ ┆ significant impact to the project, with 20 commits │ | |
| │ ┆ ┆ ┆ ┆ ┆ across various modules, including adding new │ | |
| │ ┆ ┆ ┆ ┆ ┆ features, fixing bugs, and improving test │ | |
| │ ┆ ┆ ┆ ┆ ┆ coverage. The scope of changes suggests a deep │ | |
| │ ┆ ┆ ┆ ┆ ┆ understanding of the project's architecture and │ | |
| │ ┆ ┆ ┆ ┆ ┆ requirements. The technical ability score is high │ | |
| │ ┆ ┆ ┆ ┆ ┆ due to the complexity of the changes, including │ | |
| │ ┆ ┆ ┆ ┆ ┆ modifications to multiple modules, adding new │ | |
| │ ┆ ┆ ┆ ┆ ┆ functionality, and addressing issues such as │ | |
| │ ┆ ┆ ┆ ┆ ┆ resource pool usage and virtual machine │ | |
| │ ┆ ┆ ┆ ┆ ┆ management. The contributor's ability to follow │ | |
| │ ┆ ┆ ┆ ┆ ┆ changes from upstream repositories and apply them │ | |
| │ ┆ ┆ ┆ ┆ ┆ to the project also indicates a high level of │ | |
| │ ┆ ┆ ┆ ┆ ┆ technical expertise. │ | |
| ╰────────────────────┴────────────────┴───────────────────┴───────────────────┴──────────────┴────────────────────────────────────────────────────╯ | |
| (Showing first 3 rows) |
Now, we just had to repeat this step for all 250,000 contributors. Our initial approach was to just launch API requests to OpenAI in parallel from via Daft UDFs. However, we quickly ran into the same problem as before.
Getting by rate limits:
The limit for gpt-4o-mini is 500 requests per minute, and we were getting hit by it almost instantly. What was even more problematic was that the total requests per day was 10,000, and with over 250,000 requests needed to be made, there was no chance of finishing in time.
So, we decided to spin up our own model deployment on fireworks.ai, consisting of 8 Nvidia H100 80 GB replicas running Llama 3 8B.
However, now that weren’t bottlenecked by rate limits, we realized that we weren’t maximizing our token throughput. We were only hitting around 10-20 requests per second, and our deployment wasn’t autoscaling to our max of 8. Putting some logs in our UDFs, it was pretty easy to see what was going on.
Synchronous to asynchronous requests:
All the requests were launched and received sequentially in a loop, instead of concurrently. The fix though, was simple. Since Daft’s UDFs can run arbitrary python code, it was super easy to just spin up our own asyncio event loop within the UDF, and launch all the requests simultaneously (with an additional semaphore to control concurrency).
What would have been super cool was if Daft natively supported Async UDFs, this is something we are looking into and are excited about implementing.
Finally, we were getting the 50-80 requests per second throughput we deserved, and the job finished in only a couple hours. Here’s what the final code looks like:
| @daft.udf(return_dtype=...) | |
| def analyze_commit_message(commits): | |
| async def analyze_single_commit(commit): | |
| prompt = f"You are an expert at analyzing GitHub contributions ..." | |
| result = await client.chat.completions.create( | |
| model=model, | |
| response_model=CommitQuality, | |
| messages=[{"role": "user", "content": prompt}] | |
| ) | |
| return result.model_dump() | |
| semaphore = asyncio.Semaphore(max_concurrent_requests) | |
| async def analyze_with_semaphore(*args): | |
| async with semaphore: | |
| return await analyze_single_commit(*args) | |
| tasks = [ | |
| analyze_with_semaphore(commit) | |
| for commit in commits | |
| ] | |
| async def run_tasks(): | |
| return await asyncio.gather(*tasks) | |
| results = asyncio.run(run_tasks()) | |
| return results |
Structured response models:
One final thing to mention. You may have noticed is that in the inference request, we added a response_model=CommitQuality line, but what is CommitQuality?
See, Daft’s UDFs expect a certain return type, but how can we get an AI to respond in a structured way that matches the return type? Introducing Instructor + Pydantic, which together allow you to provide response models to an LLM, guaranteeing that the output corresponds to the type that you need!
We can actually take it a step further and use pydantic-to-pyarrow, to automatically create arrow schemas from pydantic models, and subsequently auto-generate UDF decorators for us.
| def pydantic_udf(pydantic_model: pydantic.BaseModel, udf: type, **kwargs): | |
| pyarrow_schema = pydantic_to_pyarrow.get_pyarrow_schema(pydantic_model) | |
| pyarrow_dtype = pa.struct([(c, pyarrow_schema.field(c).type) for c in pyarrow_schema.names]) | |
| decorator = daft.udf(return_dtype=daft.DataType.from_arrow_type(pyarrow_dtype), **kwargs) | |
| return decorator(udf) | |
| class CommitQuality(BaseModel): | |
| impact_to_project: int = Field( | |
| ge=1, le=10, | |
| description="Score from 1-10 indicating impact to project.", | |
| ) | |
| technical_ability: int = Field( | |
| ge=1, le=10, | |
| description="Score from 1-10 indicating technical ability.", | |
| ) | |
| reason: str | |
| analyze_commit_udf = pydantic_udf(CommmitQuality, analyze_commit_message) | |
Using response models with Instructor enabled us easily convert the unstructured output of a model into a structured schema for Daft.
The end result:
At the end of two days, we produced comprehensive database of 250,000 contributors, their skills, project history, and quality scores.
Here’s a sneak peek of what the data looks like (p.s. Daft supports SQL too!):
| df = daft.read_parquet("contributor_data") | |
| daft.sql(""" | |
| SELECT | |
| author_name, | |
| author_email, | |
| commit_count, | |
| technical_ability, | |
| repo, | |
| reason | |
| FROM df | |
| WHERE | |
| LOWER(languages) LIKE '%python%' | |
| AND LOWER(keywords) LIKE '%data-processing%' | |
| ORDER BY | |
| technical_ability DESC, | |
| impact_to_project DESC, | |
| commit_count DESC; | |
| """).show() | |
| ╭─────────────────┬──────────────────────────────────────┬──────────────┬───────────────────┬───────────────────────────┬────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮ | |
| │ author_name ┆ author_email ┆ commit_count ┆ technical_ability ┆ repo ┆ reason │ | |
| │ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │ | |
| │ Utf8 ┆ Utf8 ┆ UInt64 ┆ Float64 ┆ Utf8 ┆ Utf8 │ | |
| ╞═════════════════╪══════════════════════════════════════╪══════════════╪═══════════════════╪═══════════════════════════╪════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╡ | |
| │ todd lipcon ┆ todd@apache.org ┆ 530 ┆ 9 ┆ apache/hadoop ┆ apache/hadoop: This contributor has made 530 commits, with 808,187 lines added, 32,773 lines deleted, and 840,960 lin… │ | |
| ├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤ | |
| │ utkarsh ayachit ┆ utkarsh.ayachit@kitware.com ┆ 2624 ┆ 9 ┆ Kitware/VTK ┆ Kitware/VTK: This contributor has made 2624 commits to the VTK repository, with a total of 545498 lines added, 130947… │ | |
| ├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤ | |
| │ kenneth knowles ┆ klk@google.com ┆ 1702 ┆ 9 ┆ apache/beam ┆ apache/beam: This contributor has made 1702 commits with significant code changes (214082 lines added, 172459 lines d… │ | |
| ├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤ | |
| │ gael varoquaux ┆ gael.varoquaux@normalesup.org ┆ 1603 ┆ 9 ┆ scikit-learn/scikit-learn ┆ scikit-learn/scikit-learn: The contributor has made a significant impact on the project with 1603 commits, contributi… │ | |
| ├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤ | |
| │ jeremy ashkenas ┆ jashkenas@gmail.com ┆ 1358 ┆ 9 ┆ gkz/LiveScript ┆ gkz/LiveScript: This contributor has made a significant impact on the project with 1358 commits, contributing to vari… │ | |
| ├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤ | |
| │ cushon ┆ cushon@google.com|cushon@openjdk.org ┆ 1253 ┆ 9 ┆ bazelbuild/bazel ┆ bazelbuild/bazel: The contributor has made 1253 commits with significant code changes, modifying 237575 lines, and ad… │ | |
| ├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤ | |
| │ myhloli ┆ moe@myhloli.com ┆ 1240 ┆ 9 ┆ opendatalab/MinerU ┆ opendatalab/MinerU: The contributor has made significant contributions to the project with 1240 commits and 972542 li… │ | |
| ├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤ | |
| │ chris harris ┆ chris.harris@kitware.com ┆ 970 ┆ 9 ┆ OpenChemistry/tomviz ┆ OpenChemistry/tomviz: This contributor, Chris Harris, has made 970 commits to the tomviz repository, with a high volu… │ | |
| ╰─────────────────┴──────────────────────────────────────┴──────────────┴───────────────────┴───────────────────────────┴────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯ |
Of course, we didn’t stop with just the data. As with all hackathon projects, we needed a presentable way to show our work to our judges.
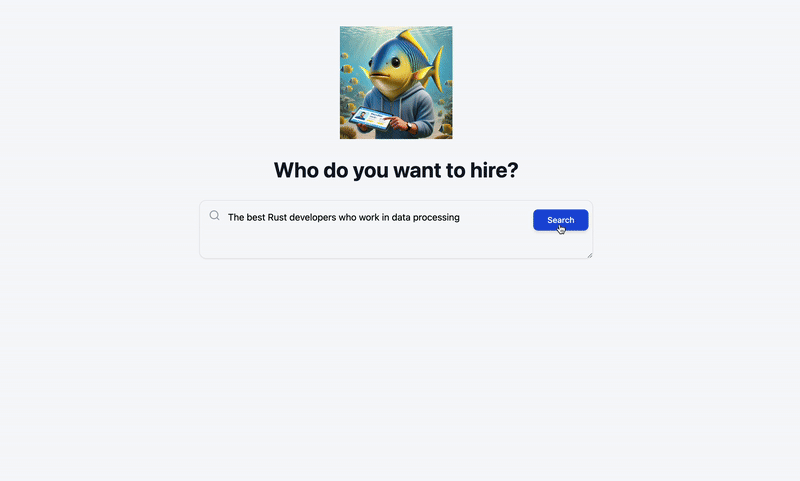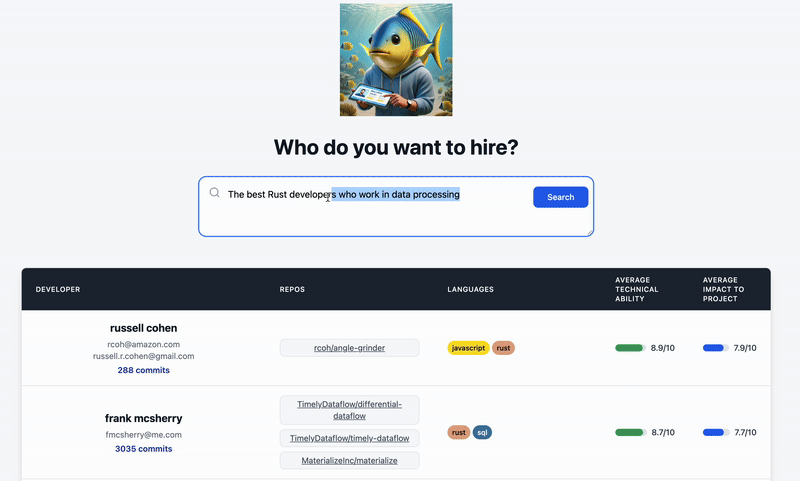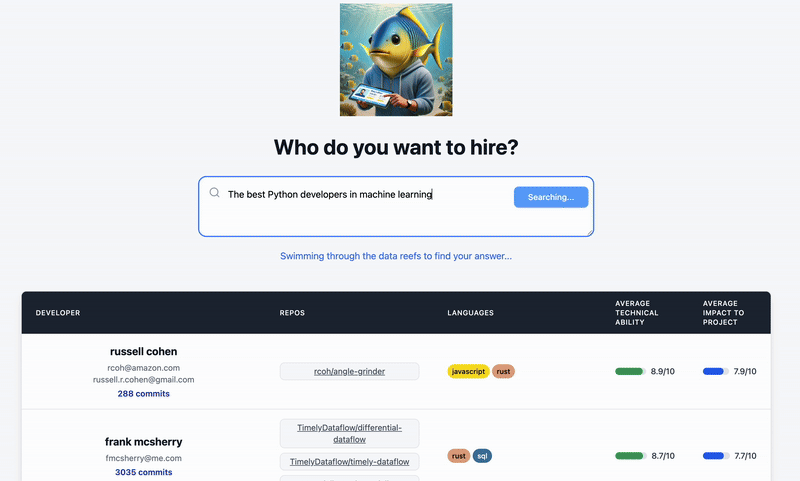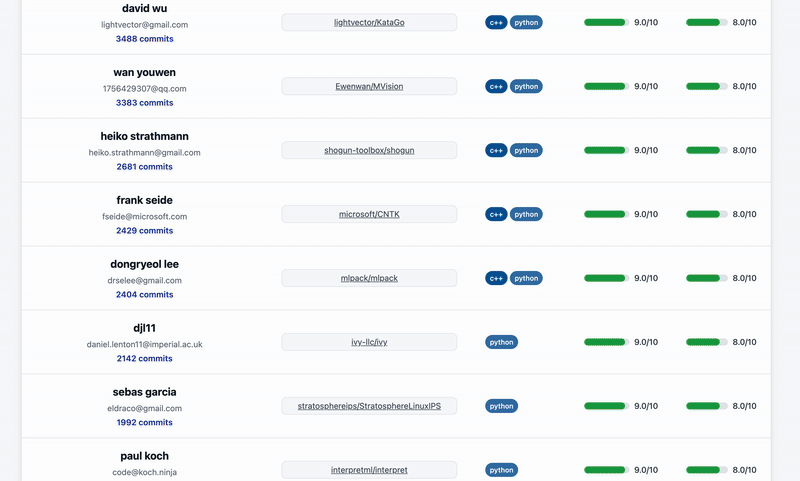
Looking for a Rust expert who's contributed to high-performance networking libraries? Or maybe someone who's a master in both machine learning and IOS development?
Search for them yourself at Sashimi4Talent 🍣
Why Daft made this possible
Looking back at this project, there are three key advantages that made Daft the perfect tool:
Flexibility through UDFs: I could run any Python code - API calls, git operations, LLM inference - in parallel over my data.
Scalability without rewrites: The same code that ran on my laptop scaled across machines when I needed more compute.
Hybrid functionality: Daft handles both traditional analytics operations (GroupBy, Join, Aggregate) AND arbitrary Python code.
These capabilities meant I could build a complex data pipeline that involved:
API requests to GitHub
Git operations for cloning and parsing commits
LLM inference for analyzing content
Traditional analytics for grouping and aggregating data
All within a single framework, and all with code that could scale from my laptop to a cluster.
Future work
While we were able to accomplish a lot in just two days, there are several improvements we're planning for the future:
Async UDFs: We know that UDFs are frequently used to make network requests, and we plan to add native support for asynchronous UDFs. This would eliminate the need for manual asyncio event loop management within UDF.
Streaming UDFs: Outputs of UDFs can often be larger than their inputs, and in order to reduce peak memory usage it makes sense to yield outputs to downstream operators as they are completed. UDFs implemented as streaming generators may be beneficial for these situations.
Enhanced observability: It’s nice to know what’s going on your program, and we plan to add detailed progress reporting and visualizations into Daft. This would provide much-needed visibility into long-running operations like LLM inference and help diagnose performance bottlenecks.
Be sure to join the Daft Community and get started with pip install daft today!
📲 Join Daft Slack | ⭐ Star Daft Repo | 📄 Daft Documentation | 💼 We’re Hiring!