
Working with the Apache Parquet file format
Quick notes written from 200 meters down the Parquet rabbit hole

In the process of building Daft we noticed a common pattern across many distributed processing workloads — data is often stored in cloud object storage (e.g. AWS S3) and in the Apache Parquet format.
The deeper I dug, the more I learned that Parquet is actually a really complex format with many hidden gotchas! Understanding Parquet is important because scanning this data format from AWS S3 is slow and is often the performance bottleneck when it comes to distributed data queries.

The Bits and Bytes in a Parquet file
Data Layout
Parquet is a “Columnar” data format. Abstractly, this means that data on disk is laid out such that data from the same column is close-together. Parquet goes one step further - it groups data by both columns AND rows:

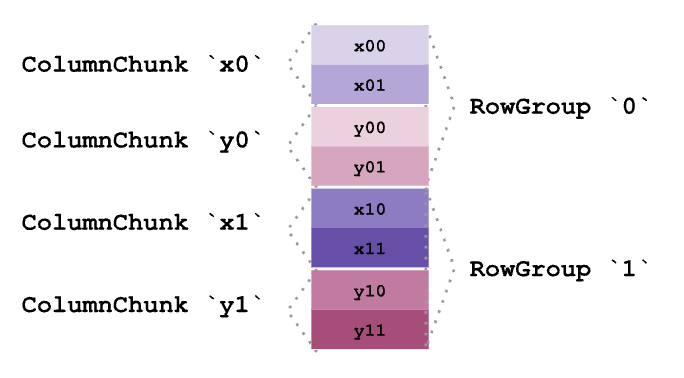
Imagine a table with two columns of data, marked here as x and y
Our table is split row-wise into RowGroups. In this example, we split the table into 2 RowGroups, giving us 4 ColumnChunks: x0, x1, y0 and y1
Each ColumnChunk is further split into Pages. In this example we have 2 Pages per ColumnChunk, yielding us a total of 8 Pages
If we peer under the hood of a Parquet file, the Pages are laid out such that:
Pages from the same ColumnChunk are in contiguous memory
ColumnChunks from the same RowGroup are also kept contiguous
The main advantage of this layout is you can now read less data1:
Better encoding and compression ratios: Encoding and compression of each Page is very efficient because each Page contains a batch of homogeneously-typed data from a column
Scanning specific rows/columns: Selectively scanning only specific rows or columns is much more efficient by only reading the required Pages
Data Serialization
Parquet is a binary file format containing Apache Thrift messages. These messages contain the metadata and statistics which help file readers navigate the Pages and scan just the data that they need.
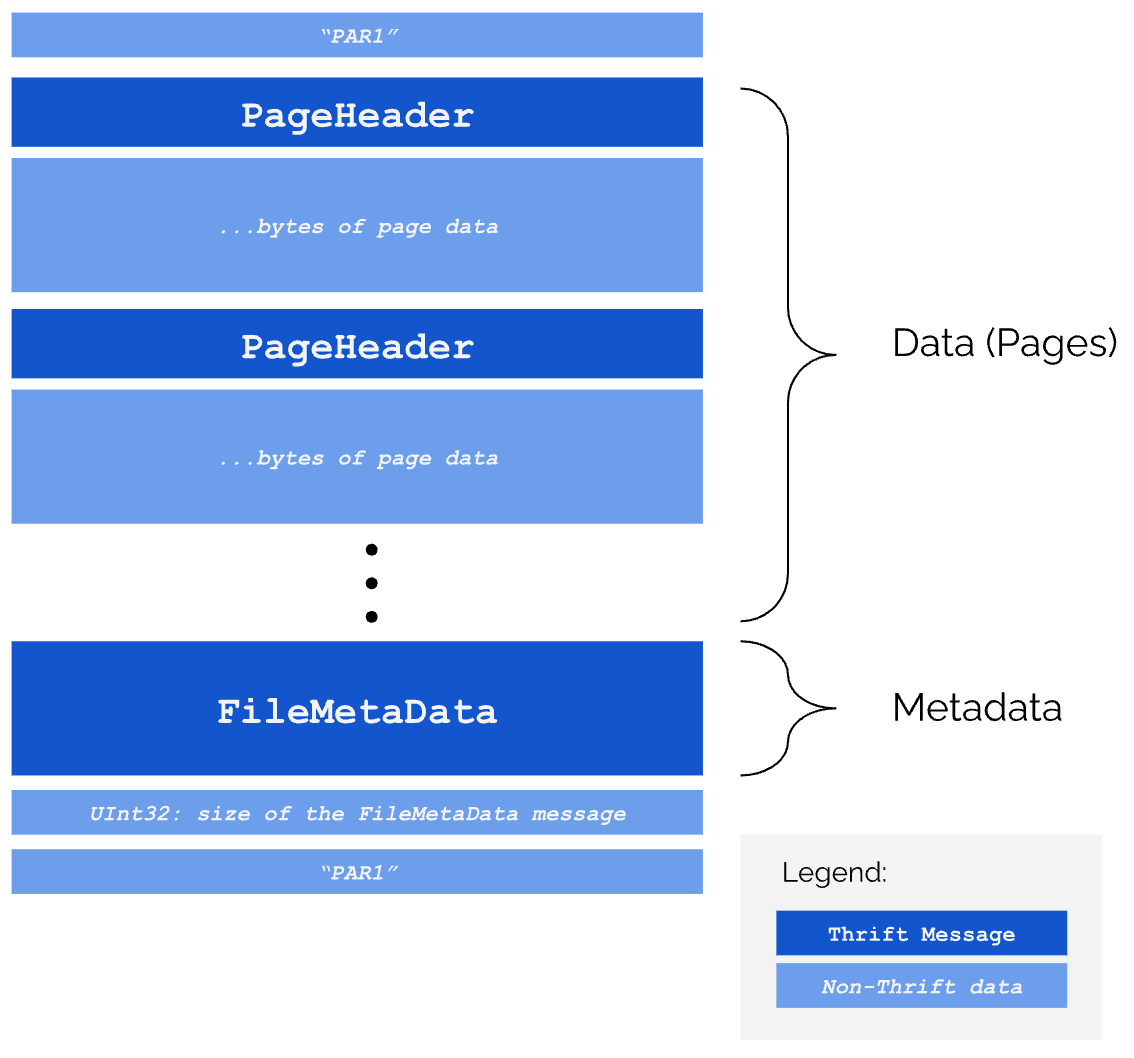
A Parquet file is split into “data” and “metadata”. The Data section contains the pages. The Metadata is mainly represented as a FileMetaData Thrift message, containing metadata, statistics and offsets to Pages.
Think of the FileMetaData as an index for your data
It can translate queries such as “find Pages from column x containing values less than 10” into the actual locations of the ColumnChunks that match this criteria
For a more in-depth exploration of the available metadata fields and statistics, you should consult the Parquet Thrift definition file. There’s a lot of them. Also a quick note - not all of them are widely used/populated by producers of Parquet data!
Pages
Finally, we can talk about the individual Page in the Parquet file.
Pages in Parquet are the atomic unit of columnar data. To read the data in a page, you’d have to:
Decompress the data: Each page can be compressed with various algorithms (e.g. Snappy, LZ4, GZip etc)
Decode the data: Each page can be encoded in different ways (e.g. Plain, Run-Length Encoding [RLE], Dictionary encodings, Delta encodings etc)
Deserialize the data based on logical type: Parquet supports a fixed limited set of physical types mapped to a (growing) set of logical types.
The implementation for reading/writing a Page is often application-specific. Frameworks such as Apache Spark have their own in-memory datastructures and implement their own optimized Page readers/writers (e.g. the Spark VectorizedColumnReader).
This leads to many problems and inconsistencies across these implementations because…
New Parquet Features
The Parquet specification is iterated on rapidly and has a semantic versioning scheme, but the use of this versioning is inconsistent and not all features are widely used.
Since the introduction of Parquet 1.0.0 in July 2013, the specification has gone through many improvements. These improvements largely fall under:
New Data Structures: DataPageV2 was introduced in 2.0.0
New Encodings: e.g. Delta encodings in 2.0.0
New Compression Algorithms: e.g. Brotli in 2.4.0
New Logical Types: e.g. unsigned integers in 2.2.0
New Metadata/Statistics: e.g. PageIndex in 2.4.0
However it’s unclear how widespread adoption for these features actually is. Because Parquet is just a file format, actual adoption of its new features is actually driven by developers of applications that are consumers/producers of Parquet such as Spark, Impala and Daft amongst many others.
There does not yet seem to be consensus in the community as to which newer features in Parquet are considered “core” and safe to use when writing.
For a more extended discussion about these problems with Parquet, there has been a proposal to define a “core” set of features in the format.
As part of this blogpost, I also built the parquet-benchmarking open-source repository which contains tools for inspecting Parquet files and listing the features that they use. Feel free to run this over your own Parquet files!
Moreover, the version flag in a Parquet file’s metadata is unreliable as a mechanism for determining what features are used in that file, since many Parquet producers just hardcode this value4. This means that a Parquet file with version=1 may actually be using features from Parquet>=2.0.0.

In 2020, developers of Trino found that producing files with features from Parquet>=2.0.0 led to various incompatibilities with many reader implementations5. For now, the conventional wisdom appears to be to write Parquet files with only the features that were available at v1.0.0 for maximum compatibility.
Encouragingly, some standardization in Parquet reading/writing seems to be happening now. What’s surprising is that this seems to be happening through a different Apache project. Let’s talk about Apache Arrow!
Parquet and Apache Arrow
It’s difficult to talk about Parquet today without addressing its “sister project” Apache Arrow. Apache Arrow is a columnar data format as well, with the main difference here being that its goal is to be an in-memory data format, rather than one that is optimized for long-term storage on disk like Parquet.
The Parquet C++ client implementation has actually been absorbed by its sister Arrow C++ project!
For a long time, if you had to build a program that needs to read Parquet data, you would likely have to build your own efficient reader of Parquet Pages into your own in-memory datastructures. The Arrow projects provide not only provide a nice home to house efficient implementations of the Parquet readers; they also provide a reasonable cross-language in-memory “destination” for this Parquet data - as Arrow tables!
This isn’t without its rough edges (for example, the two projects have slightly different type-systems and sometimes requires conversions). However for some languages such as Python, usage of Parquet is increasingly becoming synonymous with usage of Arrow under the hood. In Python, reading of Parquet data is often done using PyArrow into frameworks such as Pandas.
Because the two communities are so tightly integrated, reading the Arrow APIs actually provides some useful hints about how we can think about Parquet’s features!
In PyArrow’s Parquet write_table implementation:
It uses Parquet’s semantic versioning — but only for determining which logical types are valid to use, ignoring this semantic versioning for other features
It defaults to the v1 DataPage — but allows writing DataPageV2 if requested. There seems to be some push for defaulting to V2.
Compression defaults to “snappy” but can be configured per-column
Encodings appear to be automatically determined by the writer depending on the version of PyArrow you are using, but can also be independently controlled
Parting Thoughts
In the world of data tooling (e.g. Daft/Spark/DuckDB/Polars), there appears to be a convergence around the support for open file formats and data access patterns:
CSV for simple exploratory data
Line-delimited JSON for anything more complex or nested
Parquet for larger data or stricter schema requirements
Data Catalog + Parquet for data warehousing
Parquet is clearly here to stay and has rapidly growing adoption even for smaller datasets due to its advantages as a columnar and schemaful file format.
However, it is important to understand that Parquet is a very complex file format. Not all Parquet files are created equal! Depending on the framework you use to read/write the data, there can be many subtle differences in your files that can affect compatibility with other frameworks and read throughput.
As a next step, we will be taking a deeper look at exactly why reading Parquet data from cloud storage is slow, and what we can potentially do about it!
Special Thanks
Big shoutout to Daniel Weeks (co-creator of Apache Iceberg and Apache Parquet/Iceberg PMC member) for helping with much of the content in this blogpost!
Parquet Performance Tuning - the missing guide - talk slides by Ryan Blue on Parquet optimizations at Netflix
Go Parquet documentation on version flag in FileMetaData
Trino Issue: Native Parquet writer creates files that cannot be read by Hive and Spark: Trino issues when defaulting to writing V2 Parquet files
Looking forward to part 2. Great work!